
1. Triton Inference Server
NVIDIA Triton Inference Server — NVIDIA Triton Inference Server
<!-- # Copyright 2023-2024, NVIDIA CORPORATION & AFFILIATES. All rights reserved. # # Redistribution and use in source and binary forms, with or without # modification, are permitted provided that the following conditions # are met: # * Redistributions of
docs.nvidia.com
Triton Inference Server is an open source inference serving software that streamlines AI inferencing.
Triton Inference Server는 NVIDIA에서 제공하는 오픈소스 AI 모델 추론 서버이다.
학습된 모델을 서빙하기 위해서는 웹 개발 지식이 필요하다.
Triton은 모델 연구자에게 웹 개발에 대한 부담을 덜어주기 위한 서비스라고 생각하면 된다.
학습된 모델 파일을 model repository에 저장하면 별도의 코드를 작성할 필요 없이 해당 모델을 사용하여 추론하는 API가 제공된다.
모델을 호출할 때는 gRPC나 REST API를 통해 추론 요청을 할 수 있다.
1.1 통신 아키텍처

클라이언트의 요청을 받아 Triton Inference Server(이하 Triton Server)에게 전달하고, 추론 결과를 받아 클라이언트에게 응답하는 아키텍처이다.
Triton Server가 제공하는 API를 호출하기 위해서는 통신을 위한 라이브러리가 필요하다.
이를 위해 Triton에서는 언어 별로 구현된 클라이언트 라이브러리를 제공한다. (python의 경우 tritonclient)
1.2 참고
이번 글에서는 클라이언트 라이브러리를 사용하여 통신을 담당하는 코드를 Triton Client, 클라이언트와 통신하는 Web Framework로 Triton Client를 구현한 곳을 서버라고 지칭한다.
아키텍처를 구현하는 방법은 파이썬을 기준으로 설명한다.
2. 통신 방법
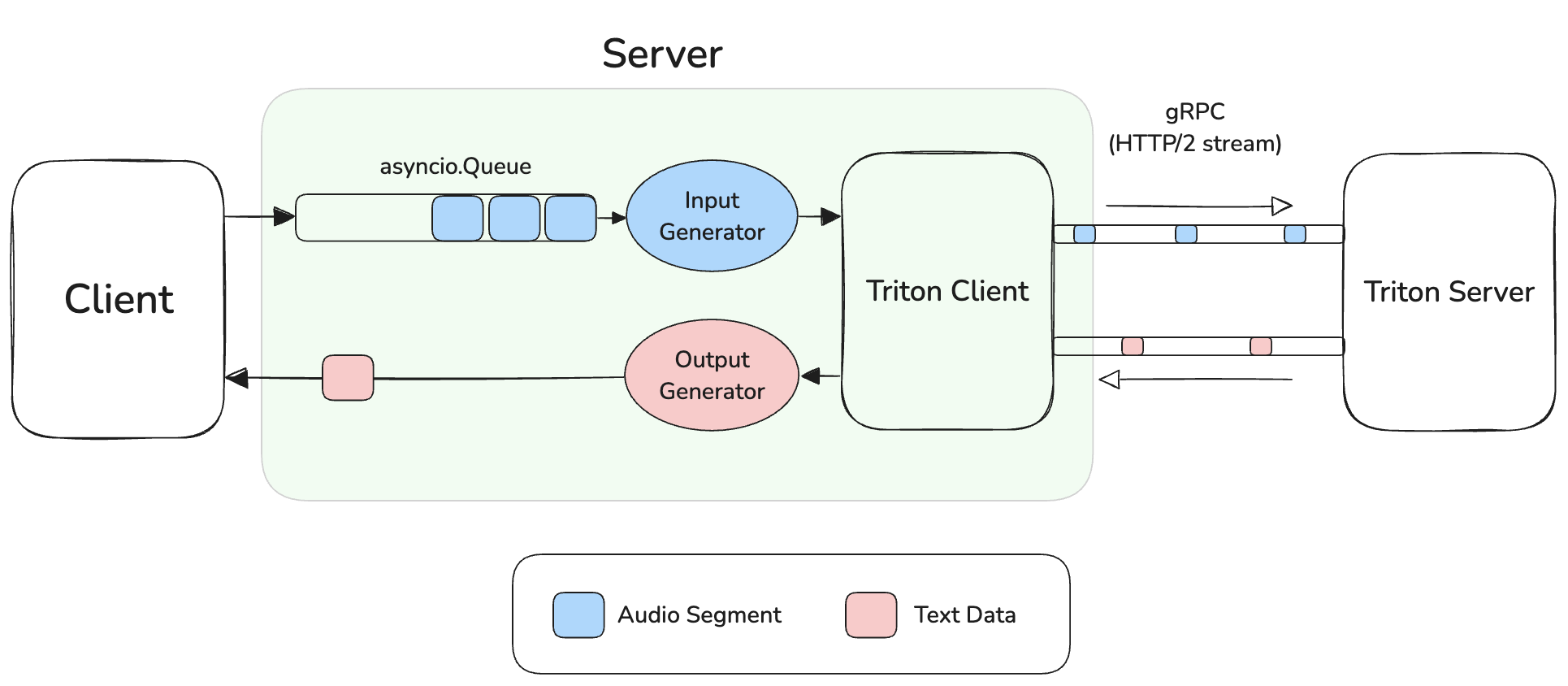
- 클라이언트로부터 음성 데이터가 들어온다.
- Input Generator가 음성 데이터를 반환한다.
- Triton Client는 Stream으로 Triton Server에게 음성 데이터를 전송한다.
- Triton Server에 서빙된 모델은 음성 데이터를 받아 추론한 뒤, 예측한 텍스트 데이터를 반환한다.
- Triton Server는 Stream으로 Triton Client에게 텍스트 데이터를 전송한다.
- Output Generator가 텍스트 데이터를 반환한다.
- 클라이언트에게 텍스트 데이터를 반환한다.
2.1 Queue가 존재하는 이유
위 아키텍처에서는 클라이언트의 음성 데이터를 Queue에 보관하였다가 이를 구독하고 있는 Generator가 Triton Client에게 반환한다.
Queue에 데이터를 담지 않고 바로 gRPC로 보내도 될 텐데 이런 구조를 선택한 이유는 무엇일까?

tritonclient.grpc.aio — NVIDIA Triton Inference Server
Note This object can be used to cancel the inference request like below: >>> it = stream_infer(...) >>> ret = it.cancel()
docs.nvidia.com
비동기 환경에서 gRPC 통신을 구현할 때는 stream_infer() 함수를 사용한다.
이 함수는 입력 데이터를 yield하는 Iterator가 필요하다.
Queue에 데이터를 담지 않고 바로 전송한다는 것은 동기적으로 처리하겠다는 것인데, stream_infer() 함수가 비동기적으로 작업을 하기에 해당 방식은 사용할 수 없다.
원하는 시점에 데이터를 전송할 수 있도록 비동기를 지원하는 Queue에 데이터를 넣고, 이를 Generator가 구독하는 방식으로 구현한다.
2.2 샘플 코드
client/src/python/examples/simple_grpc_aio_sequence_stream_infer_client.py at main · triton-inference-server/client
Triton Python, C++ and Java client libraries, and GRPC-generated client examples for go, java and scala. - triton-inference-server/client
github.com
Triton 공식 레포에서 제공하는 Client 측 샘플 코드이다.
코드 중간에 stream_infer() 함수 파트에서 Generator를 활용한 것을 볼 수 있다
3. References
NVIDIA Triton Inference Server — NVIDIA Triton Inference Server
<!-- # Copyright 2023-2024, NVIDIA CORPORATION & AFFILIATES. All rights reserved. # # Redistribution and use in source and binary forms, with or without # modification, are permitted provided that the following conditions # are met: # * Redistributions of
docs.nvidia.com
gRPC Learning (Part 1)
Basics, Unary and Server Streaming
medium.com
GitHub - triton-inference-server/client: Triton Python, C++ and Java client libraries, and GRPC-generated client examples for go
Triton Python, C++ and Java client libraries, and GRPC-generated client examples for go, java and scala. - triton-inference-server/client
github.com
tritonclient.grpc — NVIDIA Triton Inference Server
timeout (int) – The timeout value for the request, in microseconds. If the request cannot be completed within the time the server can take a model-specific action such as terminating the request. If not provided, the server will handle the request using
docs.nvidia.com
'공부' 카테고리의 다른 글
| DELETE Method와 멱등성 (0) | 2025.04.16 |
|---|---|
| FastAPI에서 StreamingResponse 활용 시 DB 세션 관리 (0) | 2025.03.30 |
| FastAPI의 페이지네이션 성능 개선기 (0) | 2025.01.30 |
| DB 암호화 방식 (0) | 2025.01.18 |
| 브라우저의 요청이 서버까지 가는 과정 (DNS 요청 과정) (0) | 2024.12.13 |




댓글